

Late-Binding parameters set at JobExecutionContext level in your Spring Batch ItemReader


Batch Jobs are especially useful when bulk-oriented, non-interactive, data or computation-intensive processing is required. Though an age-old form of data processing, batch processing, and batch jobs exist even in modern microservices and the cloud-native realm. Specifically, in the Spring ecosystem, the way to develop batch jobs is to use the Spring Batch framework.
What is the Spring Batch Framework?
Building upon the POJO-based development approach of the Spring framework, Spring Batch provides a lightweight, comprehensive framework for writing robust batch jobs.
Spring Batch provides reusable functions that are essential in processing large volumes of records, including logging/tracing, transaction management, job processing statistics, job restart, skip, and resource management. It also provides more advanced technical services and features that will enable extremely high-volume and high-performance batch jobs through optimization and partitioning techniques. Simple as well as complex, high-volume batch jobs can leverage the framework in a highly scalable manner to process significant volumes of information.
A primer on Spring Batch
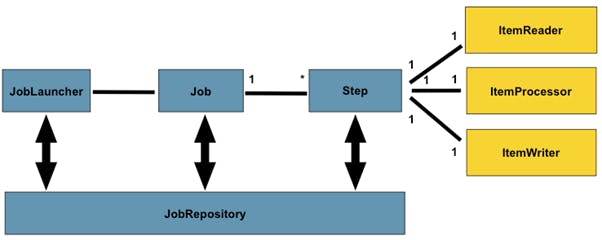 The above image from the Spring Batch documentation gives us an overview of the Spring Batch landscape and terminologies. Simply put, it follows the known batch architecture where the
The above image from the Spring Batch documentation gives us an overview of the Spring Batch landscape and terminologies. Simply put, it follows the known batch architecture where the JobRepository is responsible for scheduling and interacting with the Batch Job. The Batch Job itself composes of one or more Steps. Each Step usually follows the same approach – reads data using the ItemReader, processes it by defining some business logic inside an ItemProcessor, and writes it out by using a configured ItemWriter. This sequence can be visualized as below, as per the Spring documentation:
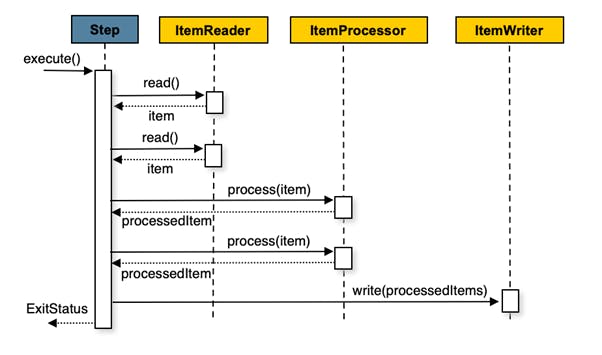
I provided a primer on Spring Batch but for the purpose of this article, I won’t be walking through how to actually write a Batch Job. I assume that you already know the basics of Spring Batch. So then, what is the scope of this article?
The Use-Case
Usually, the ItemReader in a Step of a Job reads everything from the configured source and passes it onto the ItemProcessor. However, there might be a situation where the ItemReader itself has to filter the data it is reading. Now there are certainly two ways about it:
- Read everything and have the ItemProcessor filter out the required data and discard everything else.
- Filter the data at the source itself so that the ItemProcessor is only concerned with implementing the Job logic.
In a previous internship, I came across a similar situation where I had a Flask microservice call a REST endpoint that was triggering the Batch Job. In the request body, there was a parameter value. This value had to be used to filter data when reading from the MongoDB database. What follows is an account of how I developed the solution to this Use-Case.
JobParameters
Upon reading, I found that I had to use JobParameters to pass any parameter to my Batch Job. An instance of JobParameters had to be passed as an argument to the JobLauncher.run() method. So this solved the first part of my problem i.e. how to pass a parameter to a running JobInstance of my Job.
@RestController
public class JobLauncherController {
…
@RequestMapping(value="/run", method=RequestMethod.POST)
public BaseResponseDTO runAggregatorJob(@RequestBody String parameter) throws Exception {
HashMap<String, JobParameter> params = new HashMap<>();
params.put("parameter", new JobParameter(parameter));
JobParameters jobParams = new JobParameters(params);
this.jobLauncher.run(this.aggregatorJobConfig.importAggregatorJob(), jobParameters);
return new BaseResponseDTO(“Success”, None);
}
}
Breaking down the AggregatorJobConfig
The AggregatorJobConfig class is used to set up different aspects of the batch job, for example, the Steps involved. It is usually best practice to have such a Config class with an import method that sets up the required Steps and returns a Job instance to the JobLauncher.run() method. This is how the class is written:
@Configuration
@EnableBatchProcessing
@Primary
public class AggregatorJobConfig extends DefaultBatchConfigurer {
@Autowired
public JobBuilderFactory jobBuilderFactory;
@Autowired
public StepBuilderFactory stepBuilderFactory;
private String parameter = "";
@Bean
public AggregatorJobProcessor aggregatorJobProcessor() {
return new AggregatorJobProcessor();
}
@Bean
@StepScope
public AggregatorJobReader aggregatorJobReader(
@Value("#{jobParameters['parameter']}") final String parameter) {
return new AggregatorJobReader(parameter);
}
@Bean
public AggregatorJobWriter aggregatorJobWriter() {
return new aggregatorJobWriter();
}
@Bean
public Job importAggregatorJob() {
return jobBuilderFactory.get("aggregator_job")
.incrementer(new RunIdIncrementer())
.flow(importAggregatorStep()).end().build();
}
@Bean
public Step importAggregatorStep() {
return stepBuilderFactory.get("step1").<Document, Document> chunk(10)
.reader(aggregatorJobReader(this.parameter))
.processor(aggregatorJobProcessor())
.writer(aggregatorJobWriter())
.allowStartIfComplete(true)
.build();
}
}
Starting with the importAggregatorJob(), it simply uses the JobBuilderFactory from Spring Batch to build a new Job and the flow() is defined as whatever Step is returned from the importAggregatorStep() method. A close look at the importAggregatorStep() tells us that it configures the Reader, Processor, and Writer parts of the single Step of the Job. We see that the reader is injected from the aggregatorJobReader() method. The parameter class variable is passed as an argument that flows down to the reader. This is just to ensure that the compilation passes since the JobParameter is not available when setting up the Step but only when the JobInstance is created and run.
A note on chunk()
<Document, Document> chunk(10) is for implementing a widely used Batch processing pattern called Chunk processing. This is Spring Batch configuring the Step saying that at any given time, the Step will read, process, and write in chunks of 10. The Document here simply means the bson Document from the org.bson dependency.
A note on @StepScope
If we look at the aggregatorJobReader() method definition again from the AggregatorJobConfig :
@Bean
@StepScope
public AggregatorJobReader aggregatorJobReader(@Value("#{jobParameters['parameter']}") final String parameter) {
return new AggregatorJobReader(parameter);
}
The method is annotated with @StepScope. This is required to make the Bean unique for every Step and not a singleton. So by default, Beans in Spring have a singleton scope i.e. a single copy of them is maintained in the application’s runtime context and shared with anyone who needs it. However, when we talk about the JobParameters, the parameter value may be different each time the Job is executed. So by annotating with @StepScope, we force the Reader to be instantiated newly for every step execution with whatever JobParameter that is passed to it for that particular execution. This especially proves helpful for parameter late binding where a parameter is specified either at StepContext or at the JobExecutionContext level.
Using @StepScope also allows scalability since if the same Reader is used in parallel Steps and the Reader would have been maintaining some internal state, the @StepScope will ensure that Reader in one thread does not hamper the state maintained by the Reader in another thread.
The AggregatorJobReader and how it uses the parameter
public class AggregatorJobReader implements ItemReader<Document>, ItemStream {
private MongoItemReader<Document> reader;
private final static Logger logger = LogManager.getLogger(AggregatorJobReader.class);
private String parameter;
public PlayerAggregatorJobReader(String parameter) {
this.parameter = parameter;
}
@Override
public void open(ExecutionContext arg0) throws ItemStreamException {
reader = new MongoItemReader<>();
MongoTemplate template = new MongoTemplate(
MongoInstance.INSTANCE.getClient(),
PropertyFileReader.getValue("mongoDatabaseName"));
reader.setTemplate(template);
reader.setTargetType(Document.class);
reader.setQuery("{'parameter' : " + this.parameter + "}");
reader.setCollection("…");
reader.setPageSize(10);
logger.info("IN AggregatorJobReader, MongoItemReader initialized successfully");
}
}
We simply use a constructor to initialize the parameter class member from the Config class and use it as our query when reading data by setting it on the reader variable in the open() method using the reader.setQuery() method.